MIntRec: Multimodal Intent Recognition
A New Dataset for Multimodal Intent Recognition
Statistics of the MIntRec dataset
| Total number of coarse-grained intents | 2 |
| Total number of fine-grained intents | 20 |
| Total number of videos | 43 |
| Total number of video segments | 2,224 |
| Total number of words in text utterances | 15,658 |
| Total number of unique words in text utterances | 2,562 |
| Average length of text utterances | 7.04 |
| Maximum length of text utterances | 26 |
| Average length of video segments (s) | 2.38 |
| Maximum length of video segments (s) | 9.59 |
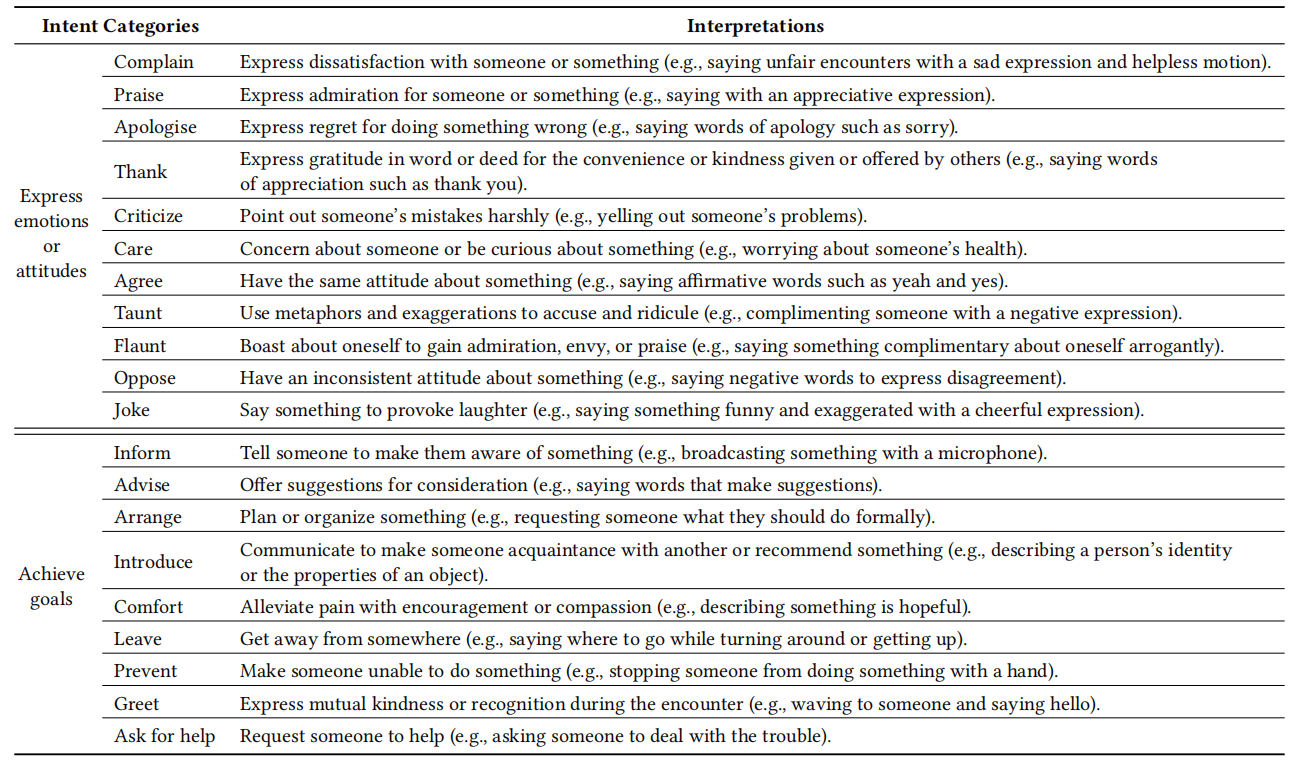
Intent taxonomies of our MIntRec dataset with brief interpretations.
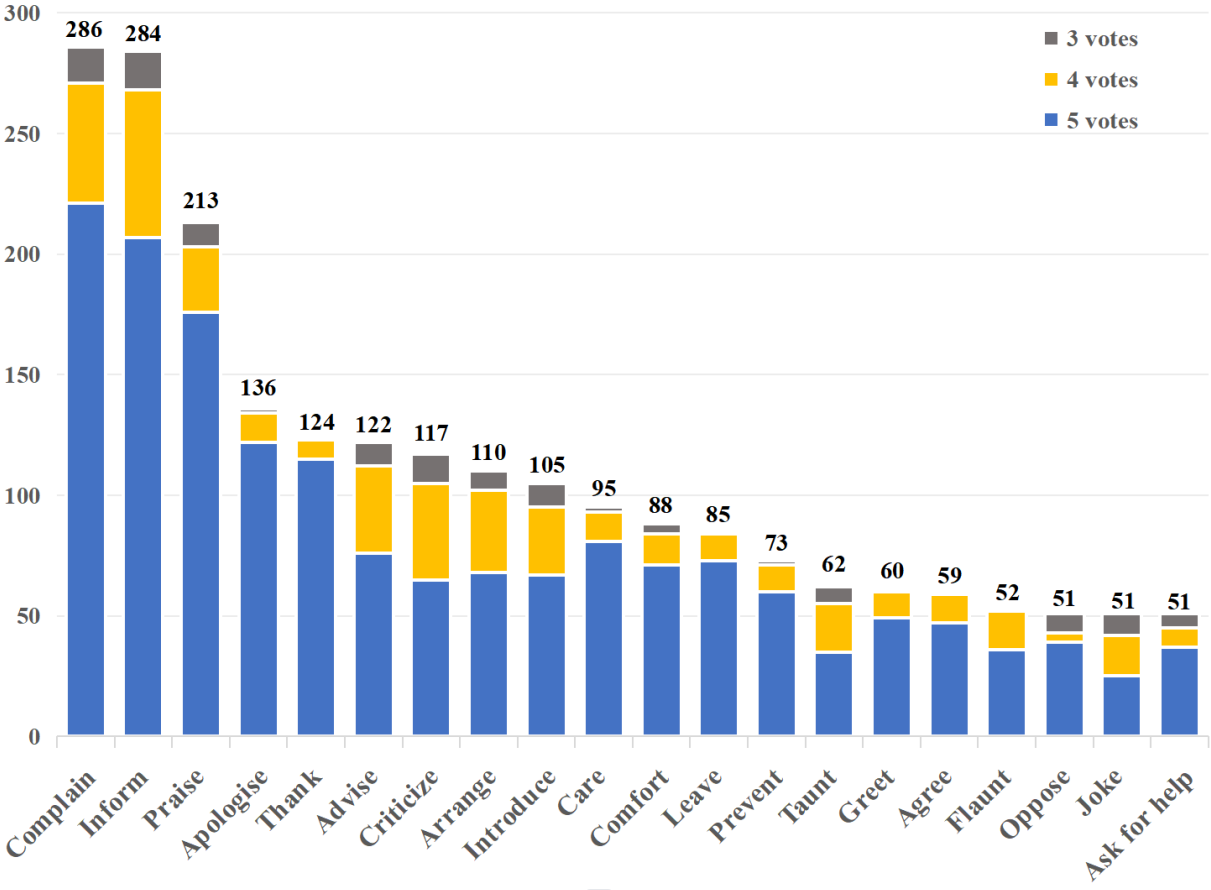
Voting statistics of 2,224 samples in MIntRec.
Citation
Please cite the following papers if you use this dataset in your work.
@inproceedings{10.1145/3503161.3547906,
author = {Zhang, Hanlei and Xu, Hua and Wang, Xin and Zhou, Qianrui and Zhao, Shaojie and Teng, Jiayan},
title = {MIntRec: A New Dataset for Multimodal Intent Recognition},
year = {2022},
doi = {10.1145/3503161.3547906},
booktitle = {Proceedings of the 30th ACM International Conference on Multimedia},
pages = {1688–1697},
numpages = {10}
}